Der Darstellung von Zeichen dient der Typ char,
– im Prinzip nicht viel mehr als eine u32-Zahl zur Kodierung von
Unicode-Zeichen. Aufgrund der strengen Typisierung wird allerdings
ein Unterschied zwischen Zeichen und Zahlen gemacht.
Genau genommen muss erst einmal erklärt sein, was man unter
»Unicode-Zeichen« genau versteht. In Unicode bekommen Zeichen und
andere semantische Informationseinheiten einen numerischen Wert
zugewiesen wie schon bei ASCII. Dieser numerische Wert wird
code point genannt, der Bereich reicht von
≥0 bis ≤0x10FFFF. Als kleine technische Komplikation kommt
allerdings noch hinzu, dass darin verbotene Surrogate-Werte enthalten
sind. Glücklicherweise sind die beiden Bereiche der Surrogate-Werte
wenigstens jeweils zusammenhängend. Schließt man diese Surrogate-Werte
aus, spricht man nun von einem unicode scalar value. Und genau
dies speichert char.
Eine Kette von solchen Skalarwerten muss nun auch irgendwie physisch auf einem Datenträger dargestellt sein. Die Darstellung als Abfolge von u32-Zahlen bezeichnet man als UTF-32-Kodierung.
Nehmen wir das bisher gesagte ernst, ist eine Umwandlung eines Zeichens in eine u32-Zahl immer durchführbar:
let x = u32::from('a');
Speziell für u8 ist die umgekehrte Umwandlung noch
allgemeingültig:
let x: u8 = 97; let c = char::from(x);
Die Umwandlung einer u32-Zahl in ein Zeichen ist aber offenbar nicht immer möglich, was es zu berücksichtigen gilt:
let x: u32 = 97;
let c = match char::try_from(x) {
Ok(value) => value,
_ => unreachable!()
};
Will man sich an fehlerhaften Eingaben nicht weiter stören, lassen sich diese auch mit einem Ersatzzeichen ignorieren:
let c = char::try_from(x).unwrap_or('?');
Werden die Zeichen wieder auf irgendeine Art der Ausgabe zugeführt,
sollte man allerdings als Ersatzzeichen eines wählen, welches nicht
in der normalen Ausgabe vorkommt. Dies bringt den Vorteil, dass man
dann Dateien mit einem Suchprogramm wie grep nach diesem
Zeichen durchsuchen kann. In Unicode ist für diesen Zweck das Zeichen
'�' mit Wert U+FFFD vorgesehen, das auch als
Konstante std::char::REPLACEMENT_CHARACTER verfügbar ist.
Eventuell möchte man einen solchen Fehler auch zumindest aufzeichnen,
damit dieser nicht unbemerkt bleibt. Das Programm gestaltet sich
dann so:
fn log_error(file: &str, line: u32, text: String) {
eprintln!("Fehler in {}:{}:\n{}", file, line, text);
}
let c = char::try_from(x).unwrap_or_else(|e| {
log_error(file!(), line!(), e.to_string());
std::char::REPLACEMENT_CHARACTER
});
Literale dienen der Angabe von Zeichenketten im Quelltext. Im einfachsten Fall steht die Zeichenkette in Anführungszeichen in einer Zeile:
let s = "Die Ordnung der Dinge";
Längere Zeichenketten passen ja nun nicht mehr in eine Zeile. Ein Zeilenumbruch im Literal ist gestattet, jedoch erzeugt dieser auch einen Zeilenumbruch in der Zeichenkette. Um dies zu verhindern, schreibt man einen Backslash an das Ende der Zeile, dann wird jeglicher Freiraum bis zum nächsten Zeichen aufgefressen. Ein äquivalente Angabe der vorherigen Zeichenkette ist demnach:
let s = "Die Ordnung \
der Dinge";
Wenn die Zeichenkette tatsächlich auch einen Umbruch enthalten soll, dann könnte man einfach schreiben:
let s = "Die Ordnung der Dinge";
Das ist jedoch etwas unästhetisch, man schreibt besser:
let s = "Die Ordnung\n\
der Dinge";
Folgende Escape-Sequenzen sind in einem Literal erlaubt.
| Sequenz | Bedeutung |
|---|---|
\n | Zeilenumbruch |
\r | Wagenrücklauf |
\t | Tabulator |
\\ | Backslash |
\' | einfaches Anführungszeichen |
\" | doppeltes Anführungszeichen |
\u{221e} | Unicode-Zeichen 0x221e |
\0 | Kurzschreibweise für \u{0}
|
\x61 | Kurzschreibweise für \u{61}
|
Dann gibt es noch die rohen Literale, bei denen keine Escape-Sequenzen vorkommen. Diese dürfen daher auch den Backslash enthalten:
let s = "\\sin(\\varphi)"; let s = r"\sin(\varphi)";
Umringt man die Anführungszeichen mit Rautezeichen, dürfen doppelte Anführungszeichen auch im Literal vorkommen:
let s = r#"<span class="a">"#;
Wenn man die Anführungszeichen mit ##
umringt, darf auch "# im Literal vorkommen,
bei ### entsprechend "## usw.
let s = r##"<a href="#id">"##;
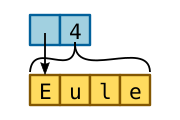
Zur Vereinfachung beschränken wir uns zunächst auf die ASCII-Kodierung, dann gehört anders als bei UTF-8 zu jedem Zeichen genau eine Speicherzelle. Wie wir eine Zeichenkette im Speicher gestalten, ist nun ganz klar, das muss ein Array von Bytes sein.
Zur genauen Darstellung gibt es mehrere Möglichkeiten. Zunächst
wäre die Festlegung einer festen Länge denkbar, also ein Typ
&[u8;N]. Für bestimmte Optimierungen, etwa bei einem
Array von kurzen Zeichenketten, kann das vorteilhaft sein, für allgemeine
Aufgaben ist es jedoch zu unflexibel. Historisch gab und gibt es
dann noch die Möglichkeit, das Ende der Kette durch ein
Terminalzeichen zu markieren, dafür wird das Zeichen mit dem
Wert null benutzt. Allerdings ist dies problematisch, da die Länge
dann nicht effizient ermittelbar ist. Zudem hat dies im Zusammenspiel
mit mangelnder Typsicherheit in der Vergangenheit oft
zu Sicherheitslücken geführt. Übrig bleibt die Möglichkeit,
Byteketten über Zeiger und Länge anzusprechen, also als
&[u8]. Das kann man tatsächlich direkt so
hinschreiben:
let a: &[u8] = &[b'E', b'u', b'l', b'e'];
println!("{:?}", a);
Die Ausgabe ist hier nicht die Zeichenkette, sondern das Array von Zahlenwerten der Zeichen in ASCII. Die Literale können wir auch kompakter notieren:
let a: &[u8] = b"Eule";
|
| Bild: Struktur einer Zeichenkette. |
Der neue Datentyp &str sorgt nun bei
Beibehaltung der Darstellung &[u8] dafür,
dass dem Array die Bedeutung einer Zeichenkette zukommt:
let s: &str = "Eule";
println!("{}", s);
Somit ist jede Zeichenkette als Bytearray betrachtbar:
let s: &str = "Eule"; let a: &[u8] = s.as_bytes();
Jedoch ist nicht jedes Bytearray eine gültige Zeichenkette:
let a: &[u8] = b"Eule"; let s: &str = std::str::from_utf8(a).unwrap();
Nebenbei bemerkt handelt es sich bei b"Eule" eigentlich
um eine Referenz auf ein Feld und nicht bloß um einen Auschnitt.
So darf man
let a: [u8; 4] = *b"Eule";
schreiben, jedoch ist
let a: [u8; 4] = *"Eule".as_bytes();
kein gangbarer Weg. Man kann in diesem Fall stattdessen
try_into heranziehen:
let a: [u8; 4] = "Eule".as_bytes().try_into().unwrap();
Manchmal ist die genaue Kodierung unbekannt. Weil die meisten Kodierungen auf ASCII aufbauen, ist es in diesem Fall ggf. pragmatisch, die Werte außerhalb ASCII zunächst durch eine Ersetzung darzustellen. Nützlich ist das außerdem für die Untersuchung von Binärdaten, die eingebettete Zeichenketten enthalten.
fn decode_ascii(a: &[u8]) -> String {
let mut acc = String::new();
for &x in a {
acc.push(if x.is_ascii() {char::from(x)} else {'?'});
}
acc
}
Eine etwas informativere Abwandlung:
fn decode_ascii(a: &[u8]) -> String {
use std::fmt::Write;
let mut acc = String::new();
for &x in a {
if x.is_ascii_graphic() || x == b' ' || x == b'\n' {
acc.push(char::from(x));
} else {
let _ = write!(acc, "[{:02x}]", x);
}
}
acc
}
Die Methode escape_ascii bietet dies bereits bequem:
fn main() {
let a: &[u8] = b"Eule";
println!("{}", a.escape_ascii());
}
Alternativ kann man auch einen sogenannten Wrapper-Typ
formulieren und für diesen Display implementieren.
Zudem ist in der Standardbibliothek eine Funktion
escape_default enthalten, die Zeichen außerhalb
des druckbaren Bereichs gegen Escape-Sequenzen ersetzt.
struct Text<'a>(&'a [u8]);
impl std::fmt::Display for Text<'_> {
fn fmt(&self, f: &mut std::fmt::Formatter) -> std::fmt::Result {
for x in self.0 {
write!(f, "{}", std::ascii::escape_default(*x))?;
}
Ok(())
}
}
fn decode_ascii(a: &[u8]) -> String {
format!("{}", Text(a))
}
So wie Arrays über Slices vom Typ &[u8] angesprochen
werden oder als Vec<u8> bezüglich ihrer Länge
dynamisch sind, gibt es eine Unterscheidung zwischen
Zeichenketten-Slices vom Typ &str und Zeichenketten
vom Typ String.
Zeichenketten vom Typ String sind in Rust dynamisch
und lassen sich als Akkumulator benutzen. Ein Akkumulator oder
akkumulierender Puffer ist eine dynamische Zeichenkette, an die
beliebig viele Zeichenketten angehängt werden können.
fn main() {
let mut acc = "".to_string();
acc += "Die";
acc += " Ordnung";
acc += " der";
acc += " Dinge";
println!("{}", acc);
}
Es folgt ein Beispiel wo ein Akkumulator mit zwei dynamischen Ketten gefüttert wird.
fn main() {
let s1 = "Text1\n".to_string();
let s2 = "Text2\n".to_string();
let mut acc = "".to_string();
acc += &s1;
acc += &s2;
println!("{}", acc);
}
Die Borrows sind notwendig, weil s1 und s2
bei diesen Operationen nicht ihren Besitz verlieren.
Die Ketten können auch von Unterprogrammen erzeugt worden sein.
fn p1() -> String {
"Text1\n".to_string()
}
fn p2() -> String {
"Text2\n".to_string()
}
fn main() {
let mut acc = "".to_string();
acc += &p1();
acc += &p2();
println!("{}", acc);
}
Ein Paar von Zahlen in eine Zeichenkette umwandeln ließe sich so bewerkstelligen:
fn pair_to_string(x: i32, y: i32) -> String {
let mut acc = String::new();
acc.push_str("(");
acc.push_str(&x.to_string());
acc.push_str(", ");
acc.push_str(&y.to_string());
acc.push_str(")");
acc
}
fn main() {
println!("{}", pair_to_string(1, 2));
}
Etwas weniger umständlich geht es auch so:
fn pair_to_string(x: i32, y: i32) -> String {
["(", &x.to_string(), ", ", &y.to_string(), ")"].join("")
}
Formatierung mit Schablonen bietet aber eine kurze und prägnante Formulierung dieser Funktion:
fn pair_to_string(x: i32, y: i32) -> String {
format!("({}, {})", x, y)
}
Das Makro format setzt Argumente in eine Schablone
ein. Die Paare von geschweiften Klammern werden durch die Argumente
ersetzt und die dadurch entstandene Zeichenkette zurückgegeben.
Das kennen wir schon vom Makro println, mit dem einzigen
Unterschied, dass die Zeichenkette dort in der Konsole ausgegeben
wird.
Die Platzhalter für die Darstellung von Zahlen im Binärsystem,
Oktalsystem und Hexadezimalsystem sind
{:b}, {:o}, {:x}.
fn bin(n: u32) -> String {format!("0b{:b}", n)}
fn oct(n: u32) -> String {format!("0o{:o}", n)}
fn hex(n: u32) -> String {format!("0x{:x}", n)}
Neben {:x} gibt es auch noch die Formatierung
{:X}, deren Unterschied in der Benutzung von
Großbuchstaben besteht.
Man kann Text in Freiraum ausrichten. Beispiele für 10 Zeichen Freiraum:
println!("|{:10}|", "Text"); // Text linksbündig ausrichten
println!("|{:<10}|", "Text"); // Text linksbündig ausrichten
println!("|{:>10}|", "Text"); // Text rechtsbündig ausrichten
println!("|{:^10}|", "Text"); // Text zentriert ausrichten
println!("|{:.<10}|", "Text"); // Punkte anstelle von Leerzeichen
println!("|{:.>10}|", "Text"); // Punkte anstelle von Leerzeichen
println!("|{:.^10}|", "Text"); // Punkte anstelle von Leerzeichen
println!("|{:10}|", 360); // Zahl rechtsbündig ausrichten
println!("|{:<10}|", 360); // Zahl linksbündig ausrichten
println!("|{:>10}|", 360); // Zahl rechtsbündig ausrichten
println!("|{:010}|", 360); // Zahl mit führenden Nullen
println!("|{:010}|", -360); // Klappt auch für negative Zahlen
Man beachte: Die Standard-Ausrichtung von Text ist linksbündig, die von Zahlen jedoch rechtsbündig. Das ist natürlich dem Umstand geschuldet, dass wir Zahlen im Dezimalsystem in »Big-Endian« aufschreiben.
Bekommt die Formatierungsangabe im Platzhalter ein Fragezeichen hinzugestellt, drückt dies die Debug-Formatierung aus, die auch Arrays erlaubt. Zusätzliche Voranstellung eines Raute-Zeichens bewirkt darüber hinaus eine Darstellung in Langform, bei der Verschachtelungen eingerückt werden.
println!("{:?}", [1, 2, 3, 4]);
println!("{:#?}", [1, 2, 3, 4]); // Zahlen untereinander
println!("{:?}", [[1, 2], [3, 4]]); // Arrays von Arrays
println!("{:#?}", [[1, 2], [3, 4]]); // Verschachtelung eingrückt
Byte-Arrays kann man dezimal oder auch hexadezimal darstellen.
println!("{:?}", b"Eule"); // Byte-Array, dezimal
println!("{:02x?}", b"Eule"); // Byte-Array, hexadezimal
Die Standardbibliothek besitzt Funktionen zum Kodieren und Dekodieren von UTF-8.
Aus didaktischen Gründen wollen wir zunächst einmal selbst einen Dekodierer für UTF-8 schreiben. Im UTF-8 sind Bytes kleiner als 128 einfache ASCII-Zeichen. Trifft man auf ein Byte ≥128, gibt es folgende drei Möglichkeiten:
0b110xxxxx 0b10xxxxxx 0b1110xxxx 0b10xxxxxx 0b10xxxxxx 0b11110xxx 0b10xxxxxx 0b10xxxxxx 0b10xxxxxx
Die Anzahl der 1-Bits vor dem 0-Bit im Startbyte ist die Anzahl n der Bytes. Die Bytesequenz besteht aus einem Startbyte und n−1 Folgebytes.
Das folgende Programm kann korrektes UTF-8 in ein Array
von Unicode-Zeichen dekodieren. Es wird auch niemals fehlschlagen,
da &str nur korrektes UTF-8 enthalten darf.
fn multibyte_count(byte: u8) -> u32 {
let mut count = 0;
for k in (0..7).rev() {
if (1<<k)&byte == 0 {break;} else {count += 1;}
}
count
}
fn chars_from_utf8(s: &str) -> Vec<char> {
let mut acc: Vec<char> = Vec::new();
let mut count = 0;
let mut c: u32 = 0;
for byte in s.bytes() {
if byte<128 {
acc.push(char::from(byte));
} else if count == 0 {
count = multibyte_count(byte);
c = u32::from(byte & match count {
1 => 0b00011111,
2 => 0b00001111,
3 => 0b00000111,
_ => unreachable!()
});
} else {
c = (c<<6) | u32::from(byte&0b00111111);
count -= 1;
if count == 0 {
acc.push(char::try_from(c).unwrap());
}
}
}
acc
}
fn main() {
println!("{:?}", chars_from_utf8("Café äöü ∀∃"));
}
Die Standardbibliothek enthält diese Funktionalität natürlich bereits:
fn main() {
let a: Vec<char> = "Café äöü ∀∃".chars().collect();
println!("{:?}", a);
}
Bei der Umwandlung von &[u8] in
&str sind Prüfungen notwendig. Hierfür steht
from_utf8 zur Verfügung:
let a: &[u8] = &[97, 98, 99, 100, 128]; let s = std::str::from_utf8(a)?;
Zusätzlich gibt es eine Funktion from_utf8_lossy,
die fehlerhaftes UTF-8 gegen das Ersatzzeichen
std::char::REPLACEMENT_CHARACTER mit dem Wert U+FFFD
ersetzt.
use std::borrow::Cow;
fn log_error(file: &str, line: u32, text: &str) {
eprintln!("{} bei {}:{}.", text, file, line);
}
fn from_utf8_lossy(a: &[u8]) -> Cow<str> {
let s = String::from_utf8_lossy(a);
if let Cow::Owned(_) = s {
log_error(file!(), line!(), "Fehlerhaftes UTF-8 detektiert");
}
return s;
}
fn main() {
let a: &[u8] = &[97, 98, 99, 100, 128];
let s = from_utf8_lossy(a);
println!("{}", s);
}
Die Länge einer Zeichenkette s bekommt man
mit dem Methodenaufruf s.len(). Hierbei handelt es
sich allerdings nicht um die Anzahl der Zeichen, sondern um die
Anzahl der Bytes. Dieser Umstand wird dadurch verschleiert, dass
die Diskrepanz bei der Untermenge ASCII noch nicht auftritt, erst
bei den UTF-8-Multibyte-Sequenzen. Bspw. gilt
"Wüste".len() == 6.
Zur Zählung der Zeichen muss die Kette zwangsläufig durchgegangen
werden, was aufwändig ist. Man schreibt hierfür
s.chars().count(). Das liefert
"Wüste".chars().count() == 5.
Eigentlich handelt es sich herbei allerdings um eine Zählung der Unicode-Skalarwerte. Die wissenschaftliche Bezeichnung für ein Zeichen lautet Graphem. In Unicode sind einige Grapheme als Zusammensetzung aus Skalarwerten darstellbar, was die Zählung weiter verkompliziert. Bei den Umlauten gehört zu jedem Graphem genau ein Skalarwert, aber auch nur dann, wenn die Zeichenkette normalisiert wurde. Bei einer nicht normalisierten Kette kann man 0x00fc (ü) auch zusammensetzen aus 0x0075 (u) und 0x0308 (Combining diaeresis). Genau genommen gibt es eine Unterscheidung zwischen Trema (Diärese) und Umlaut, aber Unicode kodiert diesen Unterschied nicht.
let s = "Wu\u{0308}ste";
println!("{}, len = {}, count = {}", s, s.len(), s.chars().count());
Die Ausgabe ist:
Wüste, len = 7, count = 6
Technisch wird diese Zusammensetzung aus Skalarwerten als Graphemkluster oder Graphemhaufen bezeichnet. Manche Grapheme können in Unicode also als Graphemkluster dargestellt sein, so die Sprechweise.
Zur allgemeinen Bestimmung der Anzahl der Grapheme bedarf es letztendlich einer Funktion, die eine Zeichenkette in Graphemkluster zerlegt – man spricht von einer Segmentierung der Kette. Solche Funktionen sind in der Standardbibliothek nicht enthalten. Sicherlich braucht auch nicht jedes Programm diese Komplexität. Wichtig wird das erst für die fortgeschrittene Verarbeitung und Darstellung von Texten.
An dieser Stelle muss einmal gesagt werden, dass Rust eine Programmiersprache mit einer gewissen Komplexität ist. Der Zeitpunkt ist günstig, dies einfach mal an den Datentypen für Zeichenketten zu verdeutlichen. In einer einfachen Programmiersprache gibt es einen Datentyp für Zeichenketten, in Rust kann man sie streng genommen nicht mehr an der Hand abzählen. Das klingt jetzt zunächst abschreckend, wäre da nicht das Prinzip der Orthogonalität.
| Typ | Erklärung |
|---|---|
&'static str
| unveränderbare UTF-8-Kette, statisch in der Binärdatei |
&'a str
| unveränderbare UTF-8-Kette mit Lebenszeit a |
String
| Besitz einer dynamischen UTF-8-Kette |
&String
| Referenz auf eine unveränderbare dynamische UTF-8-Kette |
&mut String
| Referenz auf eine veränderbare dynamische UTF-8-Kette |
Box<str>
| Besitz einer UTF-8-Kette fixer Länge |
Rc<str>
| gemeinschaftlicher Besitz unveränderbarer UTF-8-Kette |
Rc<RefCell<String>>
| gemeinschaftlicher Besitz einer dynamischen UTF-8-Kette |
Cow<str>
| Besitz einer UTF-8-Kette bei Clone-on-Write |
&'static [char]
| unveränderbare UTF-32-Kette, statisch in der Binärdatei |
&[char]
| unveränderbare UTF-32-Kette |
&mut [char]
| veränderbare UTF-32-Kette fester Länge |
Box<[char]>
| Besitz einer UTF-32-Kette fester Länge |
Vec<char>
| Besitz einer dynamischen UTF-32-Kette |
Rc<[char]>
| gemeinschaftlicher Besitz, unveränderbar |
Rc<RefCell<[char]>>
| gemeinschaftlicher Besitz, veränderbar, feste Länge |
Rc<RefCell<Vec<char>>>
| gemeinschaftlicher Besitz einer dynamischen UTF-32-Kette |
&[u8]
| unveränderbare Byte-Kette |
&mut [u8]
| veränderbare Byte-Kette fester Länge |
Vec<u8>
| Besitz einer dynamischen Byte-Kette |
&[u16]
| unveränderbare ungeprüfte UTF-16-Kette |
&mut [u16]
| veränderbare ungeprüfte UTF-16-Kette fester Länge |
Vec<u16>
| Besitz einer dynamischen ungeprüften UTF-16-Kette |
&CStr
| unveränderbare nullterminierte Kette |
CString
| Besitz einer nullterminierten dynamischen Kette |
&OsStr
| unveränderbare Kette, von plattformabhängiger Gestalt |
OsString
| Besitz einer Kette von plattformabhängiger Gestalt |
Die Typen &mut str und
Rc<RefCell<str>> dürfen nicht auf normale
Art verwendet werden, da UTF-8-Zeichenketten nicht allgemein
manipuliert werden können, ohne deren Länge zu ändern. Für solche
Aufgaben sollte der Typ &mut str in den Typ
&mut [u8] transmutiert werden. Bei der Transmutation
von &[u8] nach &str
muss man Vorsicht walten lassen, da das UTF-8 invalide sein könnte.
Hierfür ist die Funktion from_utf8 vorgesehen, die
eine Überprüfung vornimmt. Man sollte diese Funktion auch bitte
benutzen, sofern man nicht Experte ist.